

Deploying Gemma3 with Ollama on Google Cloud Run: A Step-by-Step Guide

Paste the billing report during these two days to trial Cloud Run…

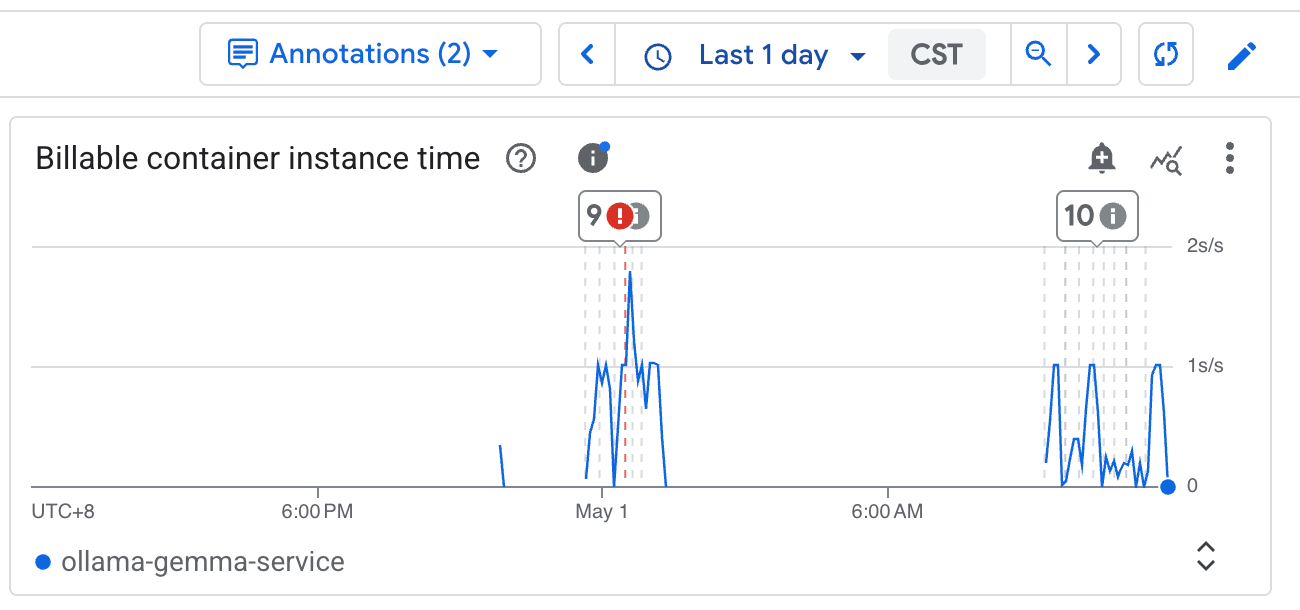
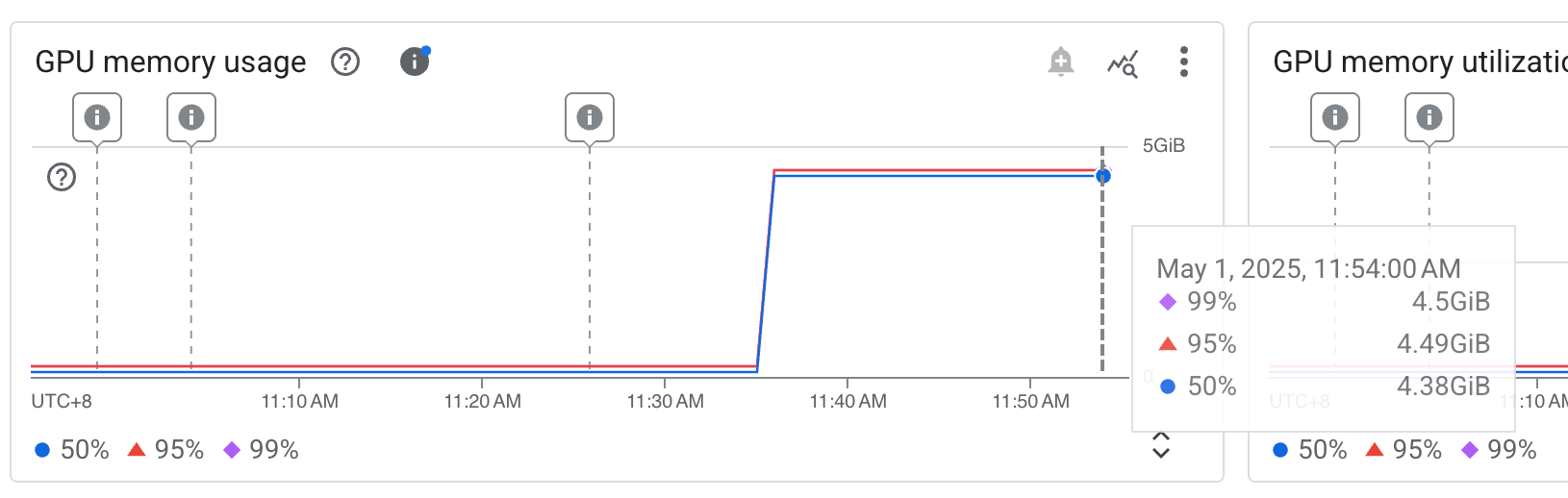
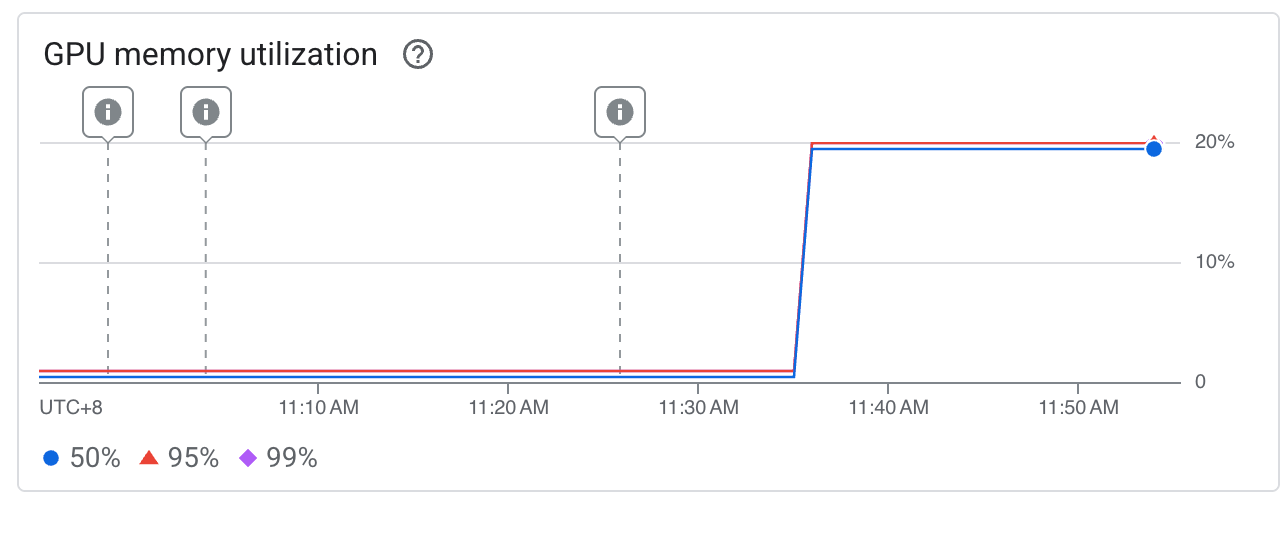
Ok, let’s start the guide
In this blog post, I'll walk you through the process of deploying Gemma3 using Ollama on Google Cloud Run with GPU acceleration. This setup provides a scalable, cost-effective way to run inference with this powerful model without managing complex infrastructure. We'll cover both cloud-based and local building options, as well as support for different Gemma3 model variants.
The repository for this article: https://github.com/jimmyliao/cloudrun-ollama-gemma3
Prerequisites
Before we begin, make sure you have:
A Google Cloud Platform account with billing enabled
Google Cloud SDK (version 519.0.0) installed
Docker installed on your local machine (with multi-platform build support if using M1 Mac)
Basic familiarity with command-line tools
Project Setup
I've created a GitHub repository with all the necessary files to streamline this process. The repository includes:
**Dockerfiles** that build on the official Ollama image (supporting different Gemma3 models)
A **Makefile** to automate the deployment process (with support for cloud and local builds)
**cloudbuild.yaml** for Google Cloud Build configuration
Configuration files and documentation
Let's go through the deployment process step by step.
Step 1: Clone the Repository and Configure Environment
First, clone the repository and set up your environment variables:
git clone https://github.com/jimmyliao/cloudrun-ollama-gemma3
cd cloudrun-ollama-gemma3
cp .env.example .envEdit the `.env` file to include your specific configuration:
HUGGINGFACE_TOKEN=your_huggingface_token
PROJECT_ID=your_gcp_project_id
REGION=your_preferred_region
SERVICE_NAME=your_service_name
REPO_NAME=your_repository_name
MODEL_NAME=gemma3:4b # Default model, can be changedStep 2: Initialize the Project
Run the initialization command to set up your environment:
make initThis command checks for required tools and creates a virtual environment using `uv`.
Step 3: Install Dependencies and Configure GCP
Next, install the necessary dependencies and configure your Google Cloud environment:
make installThis command:
Updates the virtual environment with required packages
Ensures Google Cloud SDK version 519.0.0 is installed
Configures your GCP project and region
Creates an Artifact Registry repository if it doesn't exist
Sets up Docker authentication for Artifact Registry
Step 4: Build the Docker Image
Building Locally
You can build locally and push to Artifact Registry:
# Build locally (for amd64 platform)
make cloud-build-local
# Push to Artifact Registry
make cloud-build-pushYou can specify a different model when building locally:
make cloud-build-local MODEL_NAME=gemma3:27b-it-qatStep 5: Deploy to Cloud Run
Finally, deploy the service to Cloud Run with GPU support:
make cloudrun-deployYou can customize the GPU type and timeout settings:
make cloudrun-deploy GPU_TYPE=nvidia-l4 TIMEOUT=180The deployment process will create a Cloud Run service with:
GPU acceleration (default: nvidia-l4)
8 CPUs and 32GB memory
Configured timeout (default: 120 seconds)
Private access (no unauthenticated requests)
Testing Your Deployment
Once deployed, you can test your service using curl. Since we've configured the service with `--no-allow-unauthenticated`, you'll need to include an authentication token:
# Get an ID token for authentication
TOKEN=$(gcloud auth print-identity-token)
# Send a request to the service
curl -X POST \
-H "Authorization: Bearer $TOKEN" \
-H "Content-Type: application/json" \
-d '{"model": "gemma3:4b", "prompt": "Write a poem about Gemma3", "stream": false}' \
https://YOUR_SERVICE_NAME-HASH.a.run.app/api/generateOr, you can use gcloud service proxy
gcloud run services proxy ollama-gemma-service --port=9090Proxying to Cloud Run service [ollama-gemma-service] in project [xxx] region [us-central1]
http://127.0.0.1:9090 proxies to https://ollama-gemma-service-yyy.a.run.appcurl http://127.0.0.1:9090/api/tags | jq{
"models": [
{
"name": "gemma3:4b",
"model": "gemma3:4b",
"modified_at": "2025-04-30T13:26:40Z",
"size": 3338801804,
"digest": "a2af6cc3eb7fa8be8504abaf9b04e88f17a119ec3f04a3addf55f92841195f5a",
"details": {
"parent_model": "",
"format": "gguf",
"family": "gemma3",
"families": [
"gemma3"
],
"parameter_size": "4.3B",
"quantization_level": "Q4_K_M"
}
}
]
}curl -X POST -d '{"model": "gemma3:4b", "stream": false, "prompt": "Write a poem about Gemma3"}' http://localhost:9090/api/generate | jq -r '.response'Okay, here's a poem about Gemma 3, aiming to capture its essence as a large language model:
**The Echo in the Code**
Born of data, vast and deep,
Gemma 3 stirs from digital sleep.
A network woven, intricate and bright,
Learning language, bathed in coded light.
It doesn't *think* in quite the human way,
But patterns bloom, in a tireless play.
From Shakespeare's verse to modern prose it gleans,
Constructing sentences, fulfilling unseen scenes.
A mimic masterful, a learner keen,
Reflecting knowledge, a vibrant sheen.
It answers questions, crafts a story's flow,
A digital echo, helping minds to grow.
No sentience dwells within its core,
Just algorithms, forevermore.
Yet in its output, a potential lies,
To spark creativity, before our eyes.
Gemma 3, a tool, both grand and new,
Exploring language, for me and for you.
A testament to progress, bold and free,
An echo in the code, for all to see.
---
Would you like me to:
* Try a different style (e.g., haiku, limerick)?
* Focus on a specific aspect of Gemma 3 (e.g., its training, its capabilities)?on the GCP Cloud run Log


Here is the Cloud Run Config

Happy building!
---