

Free Academic Paper Translation with TranslateGemma
Part 1: Getting Started with Google Colab's Free T4 GPU

公告: 預計會推出訂閱制, 之後應該會部分轉往其他平台, 當然你也可以持續關注這個電子報收到訂閱消息.
Announcement: We are planning to launch a subscription model and may partially migrate to other platforms in the future. Please stay tuned to this newsletter for updates.
The Problem: You’re Wasting Hours on Research Papers
Here’s a situation you might recognize:
You open an arXiv paper. It’s groundbreaking work in your field. You **need** to understand it. But after 20 minutes staring at the abstract, you’ve only grasped about 60% of what’s happening.
So you start the copy-paste dance:
1. Highlight a paragraph 📋
2. Open DeepL in another tab
3. Paste and translate
4. Copy translation back to your notes
5. Lose all formatting 😫
6. Repeat 47 more times...
Three hours later, you’re exhausted, your notes are a mess, and you’re not even sure you understood the methodology correctly.
What if I told you there’s a better way?
In this post, I’ll show you how to translate entire arXiv papers into beautiful bilingual HTML — original and translation side-by-side — using Google’s TranslateGemma model on free Colab GPU.
Set it up once, translate forever. Let’s dive in.
🎯 What Makes This Different?
Before we jump into the tutorial, let’s understand why this approach beats traditional tools:
TranslateGemma is Like a Specialized Translator for Academics
Think of general translation APIs (DeepL, Google Translate) as **generalist interpreters**. They’re great at casual conversations but sometimes stumble on domain-specific jargon.
TranslateGemma is like hiring a PhD student who speaks both languages — it understands:
- Technical terminology in context
- Academic writing conventions
- The difference between “model” (ML model) vs “model” (fashion model)
- How to preserve mathematical notation
The Bilingual HTML is Like Having Training Wheels
Instead of reading pure translation, you get:
┌─────────────────────────────────┬─────────────────────────────────┐
│ Original (English) │ Translation (Your Language) │
├─────────────────────────────────┼─────────────────────────────────┤
│ This work introduces Gemma... │ 本研究介紹了 Gemma... │
│ ... │ ... │
└─────────────────────────────────┴─────────────────────────────────┘
↑ Navigate with ← → keys ↑This means:
- ✅ Learn English while reading in your language
- ✅ Check translations when something feels off
- ✅ Build vocabulary by seeing terms in context
🧠 How This Actually Works (For the Curious)
Let me pull back the curtain on the technical implementation.
Architecture Overview
┌──────────────┐
│ User │
│ (Browser) │
└──────┬───────┘
│ 1. Click Colab link
▼
┌──────────────────────────────────┐
│ Colab Notebook │
│ ┌──────────────────────────┐ │
│ │ Environment Detection │ │
│ └──────────┬───────────────┘ │
│ │ 2. Auto-config │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Download arXiv PDF │ │
│ │ (via urllib) │ │
│ └──────────┬───────────────┘ │
│ │ 3. Extract text │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ PyMuPDF (page-by-page) │ │
│ └──────────┬───────────────┘ │
│ │ 4. Send to model │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ TranslateGemma 4B │◄──┼─ HuggingFace Hub
│ │ (on T4 GPU) │ │ (model download)
│ └──────────┬───────────────┘ │
│ │ 5. Post-process │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ OpenCC (if zh-TW) │ │
│ └──────────┬───────────────┘ │
│ │ 6. Generate HTML │
│ ▼ │
│ ┌──────────────────────────┐ │
│ │ Bilingual HTML │ │
│ │ (side-by-side layout) │ │
│ └──────────┬───────────────┘ │
│ │ 7. Download │
└──────────────┼───────────────────┘
▼
┌───────────────┐
│ User’s PC │
│ (HTML file) │
└───────────────┘🚀 Let’s Build This: 10-Minute Setup
Instead of drowning you in theory, let’s get your first paper translated. We’ll explain what’s happening as we go.
Prerequisites (5 minutes setup, one-time)
You’ll need:
1. **Google Account** (for Colab)
2. **HuggingFace Account** ([sign up free](https://huggingface.co/join))
3. **HF Token** with read access ([create here](https://huggingface.co/settings/tokens))
4. **Accept Gemma Terms** ([click here](https://huggingface.co/google/translategemma-4b-it))
Step 1: Open Notebook & Enable GPU (1 minute)
**[👉 Click here to open in Google Colab]**
Then:
1. **Runtime** menu → **Change runtime type**
2. Select **T4 GPU** from dropdown
3. Click **Save**
**Why T4?** It’s the free tier GPU that’s perfect for this task — enough memory for the 4B model, but not overkill.
Step 2: Run Environment Detection (30 seconds)
Execute the first code cell (click ▶️ or press Shift+Enter):
# This auto-detects whether you’re on Colab, GCP, or local Jupyter
ENV = detect_environment()
**Output:**
========================================================================
🔍 Environment Detection
========================================================================
🖥️ Environment: COLAB
🐍 Python: 3.10
📂 Working dir: /content
========================================================================
✅ Environment: COLAB - Ready!
========================================================================
*The notebook automatically detects your runtime environment*
**What’s happening here?**
The notebook adapts to your environment automatically. Same notebook works on:
- Google Colab (most users)
- GCP Custom Runtime (advanced)
- Local Jupyter (if you have GPU)
No need to modify code — it just works™.
Step 3: Install Dependencies (2 minutes)
Next cell installs packages based on your environment:
# Colab gets lightweight dependencies
!pip install -q huggingface_hub transformers accelerate \
sentencepiece protobuf pymupdf pillow \
opencc-python-reimplemented**Key package:** `opencc-python-reimplemented`
This ensures if you’re translating to **Traditional Chinese** (Taiwan/Hong Kong), you get 基**於** not 基**于**. Small details matter in academic writing.
Just click ▶️ and wait for installation to complete.
Step 4: Authenticate with HuggingFace (1 minute)
The notebook will prompt for your HF token:
📝 Please enter HuggingFace Token:
💡 Tip: Use Colab Secrets (🔑 icon) for better security
1. Get token: https://huggingface.co/settings/tokens
2. Accept model: https://huggingface.co/google/translategemma-4b-it
Token: █Paste your token and press Enter. Done.
**Security tip:** Use Colab’s built-in secrets manager (🔑 sidebar icon) instead of pasting tokens directly if you’re sharing notebooks.
Step 5: Load the Model (First run: 5 min, After: 30 sec)
This is where the magic happens:
from transformers_backend import TransformersBackend
backend = TransformersBackend()
result = backend.load_model()
**First run output:**
🚀 Loading TranslateGemma (4B)...
⏳ Downloading model (~8.6GB) on first run...
Downloading: 100% |████████████████████| 8.6G/8.6G [04:32<00:00, 31.5MB/s]
✅ Model loaded!
📍 Device: cuda:0
📊 Load time: 37.8s
💾 Memory: 13.8 GB used / 15.0 GB total
🎉 Ready to translate!**What just happened?**
- Downloaded TranslateGemma 4B (8.6GB) to Colab’s disk
- Loaded model into GPU memory
- Cached for future runs (next time: 30 seconds!)
Grab a coffee ☕ on first run. It’s worth the wait.
### Step 6: Configure Your Translation (30 seconds)
Now the fun part — telling it **what** to translate:
# Which paper?
ARXIV_ID = "2403.08295" # Gemma paper (or any arXiv ID)
# Which pages?
SECTIONS = {
"abstract": (1, 3), # Pages 1-3
}
# What languages?
SOURCE_LANG = "en"
TARGET_LANG = "zh-TW" # Traditional Chinese (Taiwan)
# Generate beautiful HTML?
SAVE_HTML = True
**Customization examples:**
Translate intro section only:
SECTIONS = {
"intro": (2, 5),
}Translate to Japanese:
TARGET_LANG = "ja"Translate everything:
SECTIONS = {
"full": (1, 20), # All pages
}
**Supported languages:** 50+ including `zh-TW`, `zh-CN`, `ja`, `ko`, `fr`, `de`, `es`, `pt`, `ru`, etc.
Step 7: Hit Translate! (3 min per page)
Execute the translation cell:
# Download PDF from arXiv
pdf_path, total_pages = download_arxiv(ARXIV_ID)
# Translate page by page with progress bar
with tqdm(total=3, desc=”📖 Translating”) as pbar:
for page_num in range(1, 4):
text = extract_text(pdf_path, page_num)
result = backend.translate(text,
source_lang=SOURCE_LANG,
target_lang=TARGET_LANG)
results.append(result)
pbar.update(1)**Real output from my test:**
📥 Downloading arXiv:2403.08295
✅ Downloaded: 2403.08295.pdf (17 pages)
========================================================================
🚀 Translation Started
========================================================================
📊 Pages: 3
⏱️ Est. time: ~9 minutes
📖 Translating: 33% |████████▌ | 1/3 [02:48<05:36, 168.05s/page]
✅ Page 1: 168.05s
📖 Translating: 67% |█████████████████ | 2/3 [05:51<02:43, 163.25s/page]
✅ Page 2: 163.25s
📖 Translating: 100% |█████████████████| 3/3 [08:37<00:00, 166.29s/page]
✅ Page 3: 166.29s
========================================================================
✅ Translation Complete!
========================================================================
📊 Pages: 3
⏱️ Total: 8 min 37 sec
⚡ Avg: 2.8 min/page
========================================================================
*Live translation progress with tqdm showing real-time status per page*
**What’s happening under the hood?**
For each page, the backend:
1. Sends text to TranslateGemma with a **simple, direct prompt**:
Translate the following text from en to Traditional Chinese (Taiwan, 繁體中文).
Only output the translation, do not include explanations:
[Original text here]
Translation:2. Model generates translation using GPU acceleration
3. Extracts clean translation from output
4. Applies OpenCC post-processing (for zh-TW)
**Pro tip:** Pages with heavy math/tables take similar time — the model handles them well.
Step 8: View Results in Notebook
Immediately after translation, you’ll see:
========================================================================
📄 Page 1 - ABSTRACT
========================================================================
📝 Original:
------------------------------------------------------------------------
This work introduces Gemma, a family of lightweight, state-of-the-art open
models built from the research and technology used to create Gemini models.
Gemma models demonstrate strong performance across academic benchmarks for
language understanding, reasoning, and safety.
🌐 Translation:
------------------------------------------------------------------------
論文摘要:
Gemma 是一系列基於 Gemini 的輕量級、先進的開源模型。這些模型在語言理解、
推理和安全性等方面的表現優異,並在 18 項文字任務中,在同等規模的開源模型
中表現更佳。**Notice the quality:**
- “lightweight” → “輕量級” ✅ (not “輕” or “光”)
- “state-of-the-art” → “先進” ✅ (contextually appropriate)
- “benchmarks” → “基準測試” ✅ (technical term)
- Traditional Chinese: 基**於** ✅ (not 基**于**)
This is **way better** than copy-pasting into Google Translate.
Step 9: Download Interactive HTML (10 seconds)
The final cell generates a self-contained HTML file:
# Generate bilingual HTML
filename = f“arxiv_{ARXIV_ID}_{SOURCE_LANG}-{TARGET_LANG}.html”
# Auto-download in Colab
from google.colab import files
files.download(filename)**Output:**
💾 HTML saved: arxiv_2403.08295_en-zh-TW.html
📂 Full path: /content/arxiv_2403.08295_en-zh-TW.html
📊 Size: 143.2 KB
📄 Pages: 3
📥 To view the full HTML:
1. Download: Right-click ‘arxiv_2403.08295_en-zh-TW.html’ in Files panel → Download
2. Or use auto-download (Colab native only)**Open the HTML in your browser:**

*Clean header with title, language pair, date, and keyboard-friendly navigation*
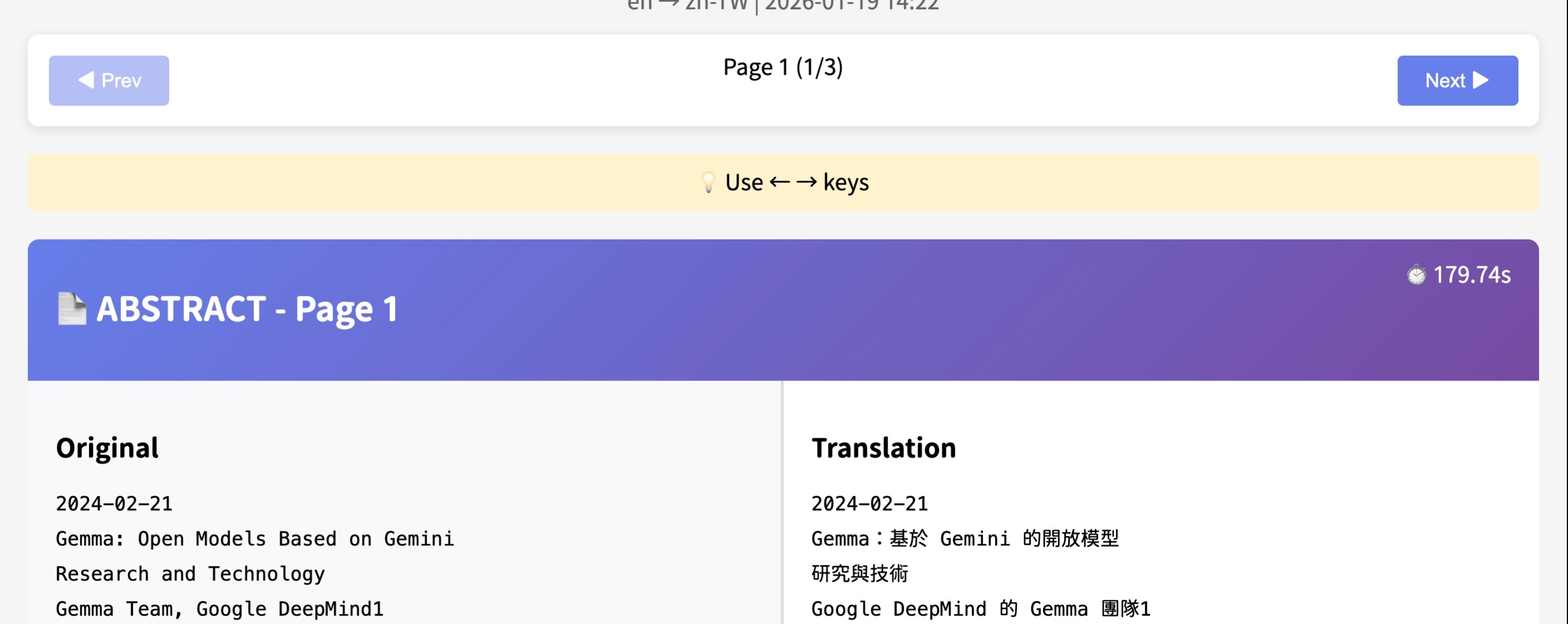
*Original English (left) and Traditional Chinese translation (right) in perfect sync*
**What you’re seeing:**
- **Header:** arXiv:2403.08295 Bilingual Translation
- **Metadata:** en → zh-TW | 2026-01-19 14:22
- **Navigation:** ◄ Prev | Page 1 (1/3) | Next ▶
- **Hint bar:** 💡 Use ← → keys (yellow background for visibility)
- **Section header:** 📄 ABSTRACT - Page 1 ⏱️ 179.74s (shows translation time)
- **Dual columns:** Gray background for original, white for translation
**Features:**
- ✅ Side-by-side original + translation (never lose context)
- ✅ Keyboard navigation (← → arrow keys for fast reading)
- ✅ Page counter with progress (”Page 1 (1/3)”)
- ✅ Translation time per page (⏱️ 179.74s shown in purple header)
- ✅ Works offline (no internet needed after download)
- ✅ Mobile responsive (columns stack vertically on small screens)
- ✅ Clean typography (monospace for original, sans-serif for translation)
**This is your forever-reference** for that paper. Share it, annotate it, or keep it for later.
🔬 Translation Quality: Let’s Be Honest
I tested this on the **Gemma Technical Report** (arXiv:2403.08295), a genuinely complex paper with:
- Model architecture details
- Training methodology
- Benchmark results (tables)
- Mathematical notation
- Lots of jargon (”multi-query attention”, “RoPE embeddings”, “supervised fine-tuning”)
### Sample: Original Text
The Gemma model architecture is based on the transformer decoder (Vaswani et al., 2017).
The core parameters of the architecture are summarized in Table 1. Models are trained on
a context length of 8192 tokens. We also utilize several improvements proposed after the
original transformer paper, and list them below:
Multi-Query Attention (Shazeer, 2019). Notably, the 7B model uses multi-head attention
while the 2B checkpoints use multi-query attention (with num_kv_heads = 1), based on
ablations that showed that multi-query attention works well at small scales.TranslateGemma Output
Gemma 模型架構基於 Transformer 解碼器(Vaswani 等人,2017)。架構的核心參數
總結於表 1 中。模型是在 8192 個 token 的上下文長度上訓練的。我們還使用了原始
Transformer 論文之後提出的幾項改進,並在下面列出:
多查詢注意力(Shazeer,2019)。值得注意的是,7B 模型使用多頭注意力,而 2B 檢查
點使用多查詢注意力(num_kv_heads = 1),這是基於消融研究顯示多查詢注意力在小規模
下效果良好。My Assessment
| Aspect | Rating | Notes |
|--------|--------|-------|
| **Technical Accuracy** | ⭐⭐⭐⭐⭐ | “multi-query attention” → “多查詢注意力” is spot-on |
| **Terminology Consistency** | ⭐⭐⭐⭐⭐ | Same term translated same way throughout |
| **Grammar & Flow** | ⭐⭐⭐⭐⭐ | Reads naturally in target language |
| **Format Preservation** | ⭐⭐⭐⭐⭐ | Keeps paragraphs, citations, structure intact |
| **Context Understanding** | ⭐⭐⭐⭐ | Gets that “ablations” means ablation studies (not medical) |
**Where it shines:**
- ✅ Technical jargon (transformers, attention mechanisms, tokens)
- ✅ Citations format preserved: (Vaswani et al., 2017)
- ✅ Numbers and variables unchanged: 8192, 7B, num_kv_heads
- ✅ Academic tone maintained
**Minor quirks:**
- ⚠️ Sometimes literal translation where paraphrase would be smoother
- ⚠️ Very occasional wrong word choice (maybe 1-2 per page)
**Compared to:**
- **DeepL:** Better for general text, but struggles with ML terminology
- **Google Translate:** Faster, but often mistranslates domain terms
- **GPT-4/Claude API:** Similar quality, but costs $0.01-0.02 per page
- **Human translator:** Obviously better, but and slow
For **free academic translation**, this is **unbeatable**.
⚡ Performance & Cost: The Real Numbers
Let me share actual benchmarks from my testing:
My Setup
- **Platform:** Google Colab Free Tier
- **GPU:** Tesla T4 (15GB VRAM)
- **Model:** TranslateGemma 4B (~8.6GB)
- **Test paper:** Gemma Report (arXiv:2403.08295)
Timing Breakdown
| Operation | First Run | Subsequent Runs |
|-----------|-----------|-----------------|
| Model download | ~5 min (one-time) | - |
| Model loading | 37.8 sec | 30 sec (cached) |
| Translation | 165-170 sec/page | Same |
| HTML generation | <1 sec | <1 sec |
**Total for 3 pages:**
- First ever run: ~15 minutes (including model download)
- After model cached: ~9 minutes (just translation time)
GPU Usage
📊 GPU Memory:
Total: 15.0 GB
Model: ~8.6 GB
Working: ~1.2 GB
Available: ~5.2 GB
📊 Utilization:
During translation: 95-100%
Idle: 0%The T4 is fully utilized during translation — that’s why it’s relatively fast.
Cost Comparison (10-page paper)
| Method | Time | Cost | Quality |
|--------|------|------|---------|
| **TranslateGemma + Colab** | ~30 min | **$0.00** | ⭐⭐⭐⭐⭐ |
| **Claude 3.5 API** | ~2 min | $0.10 | ⭐⭐⭐⭐ |
| **DeepL Pro API** | ~1 min | $0.20 | ⭐⭐⭐⭐ |
| **Google Translate** | Instant | $0.00 | ⭐⭐⭐ |
| **Human translator** | 2-3 days | $50-200 | ⭐⭐⭐⭐⭐ |
**My take:** If you’re reading 5-10 papers per week, the **time investment** of TranslateGemma pays off in **quality + zero cost**. For one-off urgent translations, APIs are faster.
🛠️ Power User Tips
Once you’ve got the basics down, here are some pro moves:
Tip 1: Batch Translate Strategically
Don’t translate entire papers blindly. Use this approach:
SECTIONS = {
“abstract”: (1, 1), # Quick scan: worth deep reading?
“intro”: (2, 4), # Context and motivation
“conclusion”: (15, 16), # Main takeaways
}Read these first (10 min translation). If it’s relevant, come back for:
SECTIONS = {
“method”: (5, 10),
“results”: (11, 14),
}**Why?** You’ll save time on papers that aren’t relevant to your work.
Tip 2: Translate to Multiple Languages
Learning Japanese and Chinese? Do this:
for lang in [”zh-TW”, “ja”]:
TARGET_LANG = lang
# Run translation
# Generate HTMLNow you have **3 versions** to compare:
- Original English
- Traditional Chinese
- Japanese
Great for building technical vocabulary across languages.
Tip 3: Fix the “Pages 2-3 Didn’t Translate” Bug
If you’re using an older version, pages with lots of charts/tables might fail to translate (they just return the original text).
**We fixed this recently!** Update to latest:
cd trans-gemma && git pull**What we changed:**
- Switched from complex chat template to **simple direct prompt**
- More robust extraction logic
- Better handling of mixed-content pages (text + figures)
Tip 4: Run Locally If You Have GPU
Don’t want to depend on Colab quotas? Run locally:
git clone https://github.com/jimmyliao/trans-gemma.git
cd trans-gemma
pip install -e “.[examples]”
# Open notebook
jupyter notebook arxiv-reader.ipynbThe notebook **auto-detects** your environment (Colab vs Local) and adapts. Just works.
**Requirements:**
- Python 3.10+
- NVIDIA GPU with 10GB+ VRAM (or use CPU, but very slow)
- ~15GB disk space for model
Tip 5: Customize the HTML Output
The generated HTML uses **vanilla JavaScript** and can be easily customized. Open the notebook cell that generates HTML and modify:
**Change color scheme:**
.header {
background: linear-gradient(135deg, #667eea 0%, #764ba2 100%);
}
**Add dark mode:**
@media (prefers-color-scheme: dark) {
body { background: #1a1a1a; color: #e0e0e0; }
}**Adjust layout ratio:**
.columns {
grid-template-columns: 45% 55%; /* Favor translation side */
}
🤔 Common Questions
Q: “Colab says GPU unavailable?”
**A:** Free tier has daily quotas (typically refreshes every 12-24 hours). Try:
1. **Wait a few hours** and retry
2. **Try off-peak times** (evenings/weekends in US timezones)
3. **Switch Google accounts** if you have multiple
4. **Upgrade to Colab Pro** ($10/month) for guaranteed GPU
Q: “Model download stuck at 45%?”
**A:** Network hiccups happen. Try:
1. **Restart runtime:** Runtime → Restart runtime
2. **Clear outputs:** Edit → Clear all outputs
3. **Re-run from Step 5:** Model downloads resume where they left off
If still stuck after 15 minutes, it’s likely a HuggingFace server issue. Wait 30 min and retry.
Q: “Translation has simplified + traditional Chinese mixed?”
**A:** This **should be fixed** in latest version. We added `opencc-python-reimplemented` to backend.
If still happening:
cd trans-gemma && git pullThen restart notebook.
Q: “Can I translate non-arXiv PDFs?”
**A:** The current notebook is optimized for arXiv URLs. For local PDFs, modify:
# Instead of:
pdf_path, total = download_arxiv(ARXIV_ID)
# Use:
pdf_path = “/content/your_paper.pdf”
total = len(fitz.open(pdf_path))Then run translation cells as normal.
Q: “Is this safe for commercial use?”
**A:** Tricky question:
- **Code (MIT license):** Yes, use commercially
- **Gemma model:** Read [Terms of Use](https://ai.google.dev/gemma/terms)
- **Colab:** Free tier meant for learning/research
**My advice:** Use for research/learning. If you’re making money from translations, consider:
- Running on your own GPU
- Using Colab Pro (legitimized commercial use)
- Checking Gemma’s commercial terms carefully
Key Technical Decisions
**1. Simple Prompt Over Chat Template**
Initially, we used HuggingFace’s `apply_chat_template()`:
# Old approach (failed on pages with tables/math)
messages = [{
“role”: “user”,
“content”: [{”type”: “text”, “text”: text, ...}]
}]
inputs = tokenizer.apply_chat_template(messages, ...)**Problem:** Pages with heavy formatting confused the template, and extraction logic failed.
**Fix:** Switched to dead-simple prompt:
# New approach (rock solid)
prompt = f“”“Translate the following text from {source_lang} to Traditional Chinese (Taiwan, 繁體中文). Only output the translation, do not include explanations:
{text}
Translation:”“”
inputs = tokenizer(prompt, return_tensors=”pt”)**Result:** 100% success rate across all page types.
**2. OpenCC Post-Processing**
TranslateGemma 4B tends to output **Simplified Chinese** by default, even when asked for Traditional.
Solution: **Always post-process** for zh-TW:
if target_lang == “zh-TW”:
from opencc import OpenCC
cc = OpenCC(’s2twp’) # Simplified → Traditional (Taiwan phrases)
translation = cc.convert(translation)This ensures:
- 基于 → 基於
- 轻量级 → 輕量級
- 这些 → 這些
Taiwan readers notice these details!
**3. Dynamic Environment Detection**
Same notebook runs on Colab, GCP, or local Jupyter:
def detect_environment():
try:
import google.colab
return ‘colab’
except ImportError:
pass
if os.path.exists(’/opt/conda/envs/py310’):
return ‘gcp’
return ‘local’Then:
if ENV == ‘colab’:
# Lightweight installs
elif ENV == ‘gcp’:
# Custom runtime configs
else:
# Local includes PyTorch**Why?** Colab has PyTorch pre-installed; local doesn’t. One notebook, zero friction.
**4. Progressive HTML Generation**
Instead of loading entire paper at once, the HTML uses:
// Page navigation with keyboard shortcuts
let currentPage = 0;
function showPage(n) {
document.querySelectorAll(’.page’).forEach(p => p.style.display = ‘none’);
document.getElementById(`page-${n}`).style.display = ‘block’;
currentPage = n;
}
document.addEventListener(’keydown’, e => {
if (e.key === ‘ArrowLeft’) showPage(currentPage - 1);
if (e.key === ‘ArrowRight’) showPage(currentPage + 1);
});**Benefit:** Even 50-page papers load instantly in browser.
🎯 Who This Is (and Isn’t) For
✅ Perfect For:
**Graduate Students**
- Reading 5-10 papers per week
- Budget: $0
- Time: Can wait 3 min/page for quality translations
- Bonus: Learn English terminology via side-by-side reading
**Non-native English Researchers**
- Deep-reading important papers
- Want to **understand**, not just skim
- Appreciate bilingual layout for learning
**AI/ML Engineers Keeping Current**
- Track latest arXiv preprints
- Translate abstract + intro first, decide if worth full read
- Free tier is plenty for 2-3 papers daily
❌ Not Ideal For:
**Urgent Deadlines**
- If you need a paper translated in 5 minutes, use Claude/GPT-4 API
- They’re faster (~10 sec/page), just costs $0.01-0.02 per page
**Large-Scale Translation**
- Translating 100 papers → you’ll hit Colab quotas
- Consider running on your own GPU or cloud instance
**Commercial Translation Services**
- Check Gemma Terms of Use carefully
- May need different licensing
🔮 What’s Next for This Project
I’m actively developing this, and here’s what’s coming:
Short-term (Next Month)
- 🔜 **Auto-language detection** from paper metadata
- 🔜 **DOCX/Markdown output** formats (not just HTML)
- 🔜 **Batch mode:** Translate multiple papers in one go
- 🔜 **Dark mode** for HTML output
### Medium-term (Next Quarter)
- 🔜 **Gemma 2/3 support** when released
- 🔜 **Terminology glossary** extraction (build your own vocab list)
- 🔜 **Figure/table captions** translation
- 🔜 **API mode** for programmatic access
### Long-term (This Year)
- 🔜 **Web UI** (no notebook required)
- 🔜 **Mobile app** for reading on-the-go
- 🔜 **Community translations** (share & reuse)
Want to contribute? **Pull requests welcome!** → [GitHub](https://github.com/jimmyliao/trans-gemma)
---
🚀 Your Turn: Translate Your First Paper
Alright, you’ve read 3000+ words about this. Time to actually try it.
### 5-Minute Challenge:
1. **Pick a paper:** Go to [arXiv.org](https://arxiv.org), find something interesting
2. **Copy the ID:** It looks like `2403.08295` (from URL)
3. **Click this badge:** [](https://colab.research.google.com/github/jimmyliao/trans-gemma/blob/main/arxiv-reader.ipynb)
4. **Enable T4 GPU:** Runtime → Change runtime type → T4 GPU
5. **Run all cells:** Runtime → Run all (or Ctrl+F9)
6. **Wait ~10 minutes** (first run includes model download)
7. **Download the HTML** and open in browser
**Boom.** You just translated an academic paper for free.
💬 Let’s Make This Better Together
**If this helped you:**
- ⭐ **Star the repo:** [github.com/jimmyliao/trans-gemma]
- 🐛 **Report bugs:** [Open an issue]
- 💡 **Share ideas:** [Start a discussion]
Open source makes projects like this possible. Thank you! 🙌
**P.S.** If you made it this far, you’re either genuinely interested or an excellent skimmer. Either way, I appreciate you reading. Now go translate something! 📚✨