

TranslateGemma:arXiv 論文翻譯工具
使用 Google TranslateGemma 模型在 Colab 免費 T4 GPU 上翻譯 arXiv 論文,產生雙語對照 HTML。

公告: 預計會推出訂閱制, 之後應該會部分轉往其他平台, 當然你也可以持續關注這個電子報收到訂閱消息.
Announcement: We are planning to launch a subscription model and may partially migrate to other platforms in the future. Please stay tuned to this newsletter for updates.
技術實作
架構
使用者
↓
Colab Notebook
├─ 環境偵測
├─ 下載 arXiv PDF (urllib)
├─ 提取文字 (PyMuPDF)
├─ 翻譯 (TranslateGemma 4B on T4 GPU)
├─ 後處理 (OpenCC for zh-TW)
└─ 產生 HTML
↓
下載到本地規格
**模型**
- TranslateGemma 4B (~8.6GB)
- 專門針對學術文本訓練
- 支援 50+ 種語言
**硬體需求**
- Google Colab 免費 T4 GPU (15GB VRAM)
- 或 macOS 16GB+ VRAM
- 或本地 NVIDIA GPU (10GB+ VRAM)
**效能**
- 每頁翻譯時間:~3 分鐘
- 首次模型下載:~5 分鐘(一次性)
- 成本:$0
前置準備
1. Google 帳號(Colab)
2. [HuggingFace 帳號](https://huggingface.co/join)
3. [HF Token](https://huggingface.co/settings/tokens)(讀取權限)
4. [接受 Gemma 使用條款](https://huggingface.co/google/translategemma-4b-it)
使用步驟
Step 1: 啟動 Notebook
**[👉 在 Google Colab 開啟](https://colab.research.google.com/github/jimmyliao/trans-gemma/blob/main/arxiv-reader.ipynb)**
啟用 GPU:
1. **Runtime** → **Change runtime type**
2. 選擇 **T4 GPU**
3. **Save**
Step 2: 環境偵測
執行第一個 cell:
ENV = detect_environment()輸出範例:
🖥️ Environment: COLAB
🐍 Python: 3.10
📂 Working dir: /content
✅ Environment: COLAB - Ready!
Notebook 自動適應 Colab/GCP/Local 環境。
Step 3: 安裝相依套件
!pip install -q huggingface_hub transformers accelerate \
sentencepiece protobuf pymupdf pillow \
opencc-python-reimplemented**關鍵套件:** `opencc-python-reimplemented`
- 將簡體中文輸出轉換為繁體中文(zh-TW)
- 確保台灣用語正確(基於 not 基于)
Step 4: HuggingFace 認證
輸入 HF token:
📝 Please enter HuggingFace Token:
1. Get token: https://huggingface.co/settings/tokens
2. Accept model: https://huggingface.co/google/translategemma-4b-it
Token: █**安全提示:** 使用 Colab Secrets (🔑) 管理 token
Step 5: 載入模型
from transformers_backend import TransformersBackend
backend = TransformersBackend()
result = backend.load_model()
首次執行輸出:
🚀 Loading TranslateGemma (4B)...
⏳ Downloading model (~8.6GB)...
Downloading: 100% |████████████| 8.6G/8.6G [04:32<00:00]
✅ Model loaded!
📍 Device: cuda:0
📊 Load time: 37.8s
💾 Memory: 13.8 GB / 15.0 GB後續執行:~30 秒(快取)
Step 6: 設定翻譯任務
# arXiv ID
ARXIV_ID = “2403.08295”
# 頁面範圍
SECTIONS = {
“abstract”: (1, 3), # 第 1-3 頁
}
# 語言設定
SOURCE_LANG = “en”
TARGET_LANG = “zh-TW” # 繁體中文(台灣)
# 產生 HTML
SAVE_HTML = True**支援語言:** `zh-TW`, `zh-CN`, `ja`, `ko`, `fr`, `de`, `es`, `pt`, `ru` 等 50+ 種
**客製化範例:**
翻譯 Abstract:
SECTIONS = {”intro”: (2, 5)}翻譯全文:
SECTIONS = {”full”: (1, 20)}翻譯成日文:
TARGET_LANG = “ja”Step 7: 執行翻譯
# 下載 PDF
pdf_path, total_pages = download_arxiv(ARXIV_ID)
# 翻譯
with tqdm(total=3, desc=”📖 Translating”) as pbar:
for page_num in range(1, 4):
text = extract_text(pdf_path, page_num)
result = backend.translate(text,
source_lang=SOURCE_LANG,
target_lang=TARGET_LANG)
results.append(result)
pbar.update(1)實測輸出:
📥 Downloading arXiv:2403.08295
✅ Downloaded: 2403.08295.pdf (17 pages)
🚀 Translation Started
📊 Pages: 3
⏱️ Est. time: ~9 minutes
📖 Translating: 33% |████████▌ | 1/3 [02:48<05:36, 168.05s]
✅ Page 1: 168.05s
📖 Translating: 67% |█████████████| 2/3 [05:51<02:43, 163.25s]
✅ Page 2: 163.25s
📖 Translating: 100% |████████████| 3/3 [08:37<00:00, 166.29s]
✅ Page 3: 166.29s
✅ Translation Complete!
📊 Total: 8 min 37 sec
⚡ Avg: 2.8 min/page
Step 8: 查看結果
Notebook 輸出:
================================================================================
📄 Page 1 - ABSTRACT
================================================================================
📝 Original:
--------------------------------------------------------------------------------
This work introduces Gemma, a family of lightweight, state-of-the-art open
models built from the research and technology used to create Gemini models.
🌐 Translation:
--------------------------------------------------------------------------------
論文摘要:
Gemma 是一系列基於 Gemini 的輕量級、先進的開源模型。這些模型在語言理解、
推理和安全性等方面的表現優異。Step 9: 下載雙語 HTML
filename = f“arxiv_{ARXIV_ID}_{SOURCE_LANG}-{TARGET_LANG}.html”
from google.colab import files
files.download(filename)輸出:
💾 HTML saved: arxiv_2403.08295_en-zh-TW.html
📊 Size: 143.2 KB
📄 Pages: 3HTML 功能

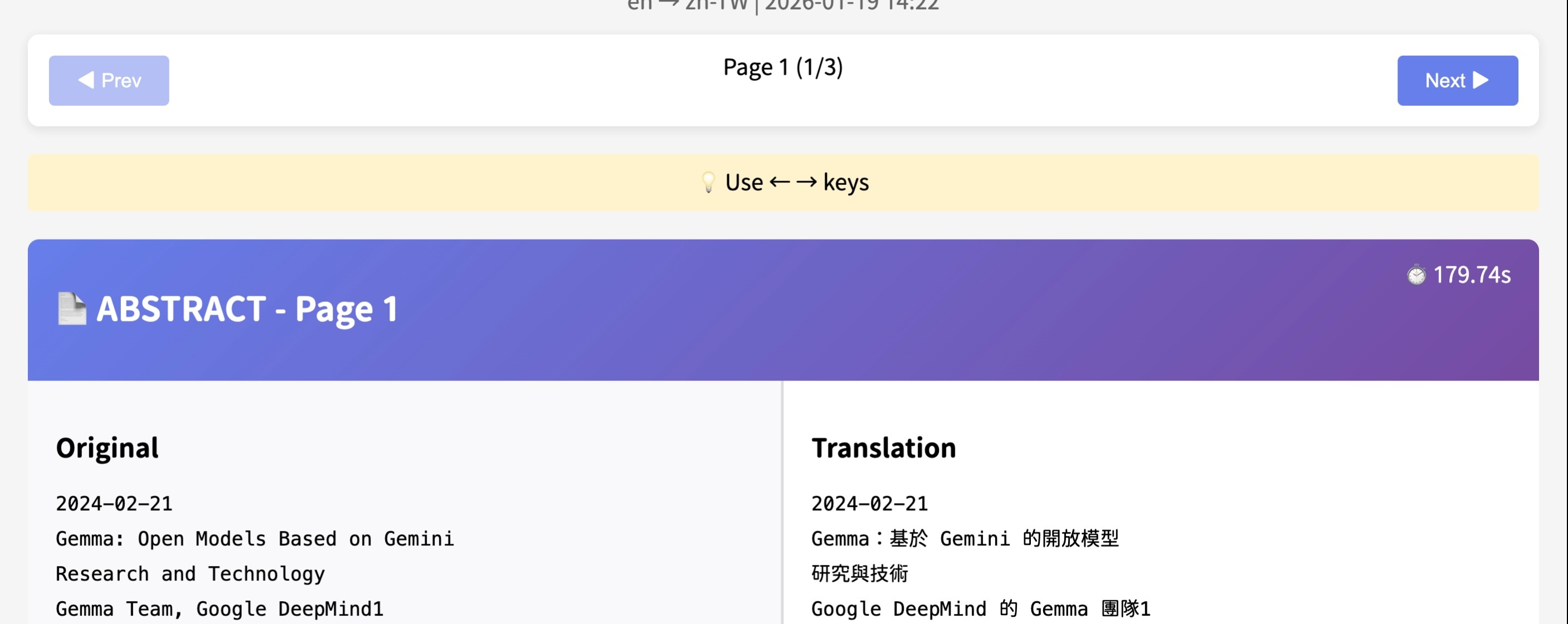
**介面組成:**
- Header:arXiv ID、語言對、產生日期
- Navigation:上一頁/下一頁按鈕
- 提示列:鍵盤操作說明(← → 鍵)
- 章節標題:頁碼、翻譯時間
- 雙欄佈局:原文(左)、翻譯(右)
**功能:**
- 原文與翻譯並排對照
- 鍵盤導航(← → 方向鍵)
- 頁面計數器(1/3)
- 顯示每頁翻譯時間
- 離線可用
- 響應式設計
翻譯品質評估
測試論文:Gemma Technical Report (arXiv:2403.08295)
測試範例
**原文:**
The Gemma model architecture is based on the transformer decoder (Vaswani et al., 2017).
Models are trained on a context length of 8192 tokens. We also utilize several improvements
proposed after the original transformer paper.
Multi-Query Attention (Shazeer, 2019). Notably, the 7B model uses multi-head attention
while the 2B checkpoints use multi-query attention (with num_kv_heads = 1).**TranslateGemma 輸出:**
Gemma 模型架構基於 Transformer 解碼器(Vaswani 等人,2017)。模型是在 8192 個
token 的上下文長度上訓練的。我們還使用了原始 Transformer 論文之後提出的幾項改進。
多查詢注意力(Shazeer,2019)。值得注意的是,7B 模型使用多頭注意力,而 2B 檢查點
使用多查詢注意力(num_kv_heads = 1)。GPU 使用
📊 GPU 記憶體:
Total: 15.0 GB
Model: ~8.6 GB
Working: ~1.2 GB
Available: ~5.2 GB
📊 使用率:
翻譯中:95-100%
閒置:0%進階使用
先翻譯重點章節:
SECTIONS = {
“abstract”: (1, 1), # 快速瀏覽
“intro”: (2, 4), # 背景動機
“conclusion”: (15, 16), # 結論
}
確認相關後再翻譯全文:
SECTIONS = {
“method”: (5, 10),
“results”: (11, 14),
}多語言翻譯
for lang in [”zh-TW”, “ja”]:
TARGET_LANG = lang
# 執行翻譯產生 3 個版本對照:
- 原始英文
- 繁體中文
- 日文
**GitHub:** [github.com/jimmyliao/trans-gemma]