來信刊登: 關於 Vertex AI Text Embedding 的非英語支援
原 "吉米筆記本" 改成 "Brew and Build",網址換成 https://brewbuild.substack.com/

有之前的社群朋友透過朋友詢問,回報 Vertex / Gemini Embedding Model 並不支援非英語的語言,於是打算來直接實驗一下。
相關程式碼在這: vertex.ipynb
先定義一下計算 cosine similarity 的函數
import numpy as np
def cosine_similarity(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))```包裝一下呼叫 Vertex AI Text Embedding API 的函數
from vertexai.language_models import TextEmbeddingInput, TextEmbeddingModel
def embed_text(
model_name: str,
task_type: str,
text: str,
title: str = "",
output_dimensionality=None,
) -> list:
"""Generates a text embedding with a Large Language Model."""
model = TextEmbeddingModel.from_pretrained(model_name)
text_embedding_input = TextEmbeddingInput(
task_type=task_type, title=title, text=text
)
kwargs = (
dict(output_dimensionality=output_dimensionality)
if output_dimensionality
else {}
)
embeddings = model.get_embeddings([text_embedding_input], **kwargs)
return embeddings[0].values其中,model_name 指定 Vertext AI Text Embedding API 的模型名稱,task_type 指定任務類型,text 指定要轉換的文字,title 可以指定標題,output_dimensionality 可以指定輸出的維度。
舉例來說,透過這種方式
MODEL = "text-embedding-004" # 呼叫 `text-embedding-004`
TASK = "RETRIEVAL_DOCUMENT"
TEXT = "This is a test"
TITLE = "Test"
OUTPUT_DIMENSIONALITY = 768
# Get a text embedding for a downstream task.
embedding = embed_text(
model_name=MODEL,
task_type=TASK,
text=TEXT,
title=TITLE,
output_dimensionality=OUTPUT_DIMENSIONALITY,
)
print(embedding)輸出會是
[0.010671528056263924, -0.0069691999815404415, -0.07482928782701492, -0.022868942469358444, 0.024032343178987503]開始實驗中文兩個文字的 cosine similarity
MODEL = "text-embedding-004" # 呼叫 `text-embedding-004`
TASK = "RETRIEVAL_DOCUMENT"
TEXT1 = "今天天氣很好"
TEXT2 = "我很開心"
embedding1 = embed_text(
model_name=MODEL,
task_type=TASK,
text=TEXT1,
title=TITLE,
output_dimensionality=OUTPUT_DIMENSIONALITY,
)
embedding2 = embed_text(
model_name=MODEL,
task_type=TASK,
text=TEXT2,
title=TITLE,
output_dimensionality=OUTPUT_DIMENSIONALITY,
)
print(embedding1[:5])
print(embedding2[:5])
similarity = cosine_similarity(embedding1, embedding2)
print(f"Similarity between '{TEXT1}' and '{TEXT2}': {similarity:.4f}")輸出
[0.008668964728713036, 0.04154808074235916, -0.029312308877706528, -0.0027766868006438017, 0.044972509145736694]
[0.008668964728713036, 0.04154808074235916, -0.029312308877706528, -0.0027766868006438017, 0.044972509145736694]
Similarity between '今天天氣很好' and '我很開心': 1.0000什麼,兩個 embedding values 一模一樣,cosine similarity 為 1.0,這是怎麼回事?
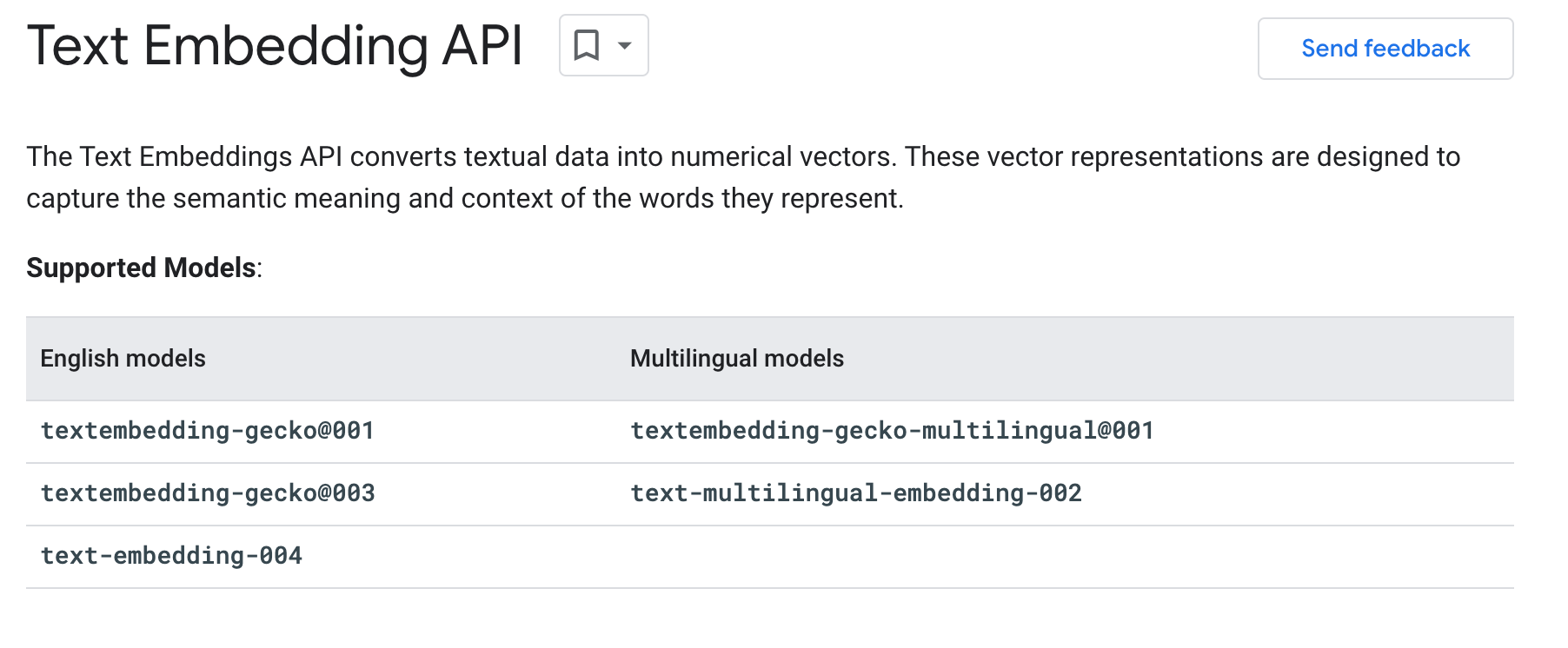
結論: 改用 `text-multilingual-embedding-002`,請認明有註記 `multilingual` 的模型
# Switch to text-multilingual-embedding-002
MODEL = "text-multilingual-embedding-002"
embedding1 = embed_text(
model_name=MODEL,
task_type=TASK,
text=TEXT1,
title=TITLE,
output_dimensionality=OUTPUT_DIMENSIONALITY,
)
embedding2 = embed_text(
model_name=MODEL,
task_type=TASK,
text=TEXT2,
title=TITLE,
output_dimensionality=OUTPUT_DIMENSIONALITY,
)
print(embedding1[:5])
print(embedding2[:5])不用計算也知道兩個 Embedding 不一樣了
[0.012177991680800915, 0.00998682714998722, 0.015519461594522, 0.0241247545927763, 0.04559287056326866]
[0.0038432718720287085, -0.021820055320858955, 0.036357633769512177, 0.02820320427417755, -0.0013248010072857141]看到這邊,是不是很想翻桌,才發現有這頁,講的倒是有點含糊 😶
https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings?hl=en
There are a few versions available for embeddings. text-embedding-004 is the newest stable embedding model with enhanced AI quality, and text-multilingual-embedding-002 is a model optimized for a wide range of non-English languages.
然後找到這頁才算是有個比較表格
https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/text-embeddings-api